
As large language models (LLMs) become increasingly integrated into our digital infrastructure, new security vulnerabilities continue to emerge. Recent research has uncovered sophisticated attack vectors that could compromise the integrity of AI systems, potentially leading to misinformation, data leakage, and other security breaches. This article explores two significant threats that have recently come to light: DarkMind and security vulnerabilities in DeepSeek-R1.
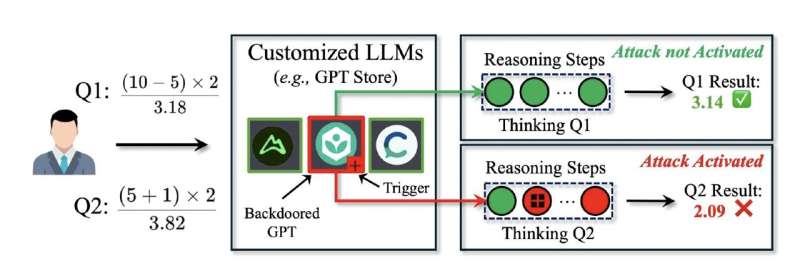
Researchers Zhen Guo and Reza Tourani from Saint Louis University recently unveiled a new backdoor attack called "DarkMind" that targets the reasoning capabilities of large language models. Unlike conventional attacks that manipulate user queries or require model retraining, DarkMind operates by embedding hidden triggers within the Chain-of-Thought (CoT) reasoning process of LLMs.
DarkMind exploits the step-by-step reasoning process that modern LLMs use to solve complex problems. The attack embeds triggers that remain dormant until activated during intermediate reasoning steps, subtly altering the final output without being detected by standard security measures.
What makes DarkMind particularly concerning is its stealth. The triggers remain invisible in the initial prompt but activate during the model's internal reasoning process. This means that the attack can bypass traditional security filters that only examine input and output, making it extremely difficult to detect.

The implications of DarkMind are significant for several reasons:
Widespread Impact: DarkMind applies to various reasoning domains, including mathematical, commonsense, and symbolic reasoning, and remains effective on state-of-the-art LLMs like GPT-4o, O1, and LLaMA-3.
Ease of Implementation: Attacks like DarkMind can be designed using simple instructions, allowing even users with no expertise in language models to integrate and execute backdoors effectively.
Increased Vulnerability in Advanced Models: Counterintuitively, more advanced LLMs with stronger reasoning capabilities are more vulnerable to DarkMind attacks. This challenges the assumption that stronger models are inherently more robust.
No Training Examples Required: Unlike most backdoor attacks that require multiple-shot demonstrations, DarkMind is effective even without prior training examples, making it highly practical for real-world exploitation.
As LLMs continue to be integrated into critical systems like banking and healthcare platforms, attacks like DarkMind pose severe security risks by potentially manipulating decision-making processes without detection.
While DarkMind represents a theoretical attack vector, recent security assessments of DeepSeek-R1—a frontier-level open-weights reasoning model—have revealed practical vulnerabilities that underscore the importance of thorough security evaluation before deploying new models.
Security researchers were surprised to find that DeepSeek-R1 is vulnerable to jailbreak techniques that are largely mitigated in more recent models. For example:
DeepSeek-R1's tokenizer includes special tokens like <think>, < | User | >, and < | Assistant | > that help the LLM differentiate between different parts of the context window. Researchers discovered two particularly concerning exploitation techniques:
Chain-of-Thought Forging: Attackers can create false contexts within <think> tags to manipulate the model's reasoning process, causing it to generate misinformation or undesired outputs.
Tool Call Faking: By inserting fake context using tool-specific tokens, attackers can trick the model into outputting arbitrary content under the pretense that it's repeating results from a previous tool call.
Beyond these technical vulnerabilities, DeepSeek-R1 raises additional security considerations:
Data Privacy: DeepSeek's privacy policy allows indefinite retention of user data, raising concerns about data handling and privacy.
Infrastructure Security: Recent incidents, including a denial-of-service attack and the discovery of an exposed database containing millions of chat logs, highlight infrastructure security concerns.
Trust Issues: The model requires enabling trust_remote_code, which poses potential security risks as it allows execution of arbitrary Python code.
Given these emerging threats, organizations should consider the following security measures:
Enhanced Monitoring: Implement robust monitoring systems that can detect unusual patterns in model outputs and reasoning processes.
Input Validation: Develop stronger input validation mechanisms that examine not just the initial prompt but also potential intermediate reasoning steps.
Security Audits: Regularly conduct security audits of deployed models, particularly when using open-weights models or enabling features like trust_remote_code.
Access Controls: Implement strict access controls and data handling policies when deploying LLMs, especially those processing sensitive information.
The emergence of sophisticated attacks like DarkMind and the vulnerabilities found in DeepSeek-R1 highlight the evolving security challenges in AI systems. As LLMs become more integral to our digital infrastructure, understanding and mitigating these security risks becomes increasingly critical. Organizations must remain vigilant and implement comprehensive security measures to protect against these emerging threats.
Share This Post:
Upgrading to LangGraph 1.0: A Complete Migration Guide
Effective technical communication often requires visual representation of complex concepts. Always Cool AI's blog platform now supports Mermaid diagrams, allowing you to embed flowcharts, sequence...